The Best Speech Recognition API in 2025: A Head-to-Head Comparison
Feb 6, 2025
Speech-to-text technology has improved dramatically in recent years, but with so many options available, which API delivers the best accuracy? In this benchmark, I test and compare the major speech recognition APIs, including cloud-based services from AWS, Google Cloud, and Microsoft Azure, two startups specializing in ASR: Assembly AI and Deepgram, the open-source OpenAI Whisper model, and Google Gemini, a large language model that can process speech input.
For this benchmark, I ran all these APIs through a series of tests covering different types of speech—clean, noisy, accented, and technical—to see how well they handle real-world transcription tasks. The goal is simple: find out which API delivers the best accuracy, and where each one struggles.
The Problem with Speech Recognition Benchmarks
You might assume that with so many speech-to-text models available, there would already be a clear answer about which one is best. Well, kind of. There are plenty of academic papers on ASR, but they mostly compare models, not APIs: APIs are problematic to benchmark for an academic setting because you don’t know exactly what’s inside, and companies can update them at any time. But most developers just want to call an API, and pick a service that just works, and are not interested in setting up and running a model locally.
I did find a few comparisons online, but many were published by companies that sell their own speech recognition APIs, eg this blog post by Deepgram, unsurprisingly ranks Deepgram as the best-performing API in every category. That’s exactly what you’d expect from a company trying to sell its own product so it's hard to find a truly unbiased evaluation.
In my case, I just wanted the best speech recognition for Voice Writer. It needs to transcribe speech in real time while fixing grammar and punctuation, so speech recognition model is crucial for the product to work well. I have no affiliation with any of these companies, so this benchmark is purely about finding what is objectively the best speech-to-text API based on real world performance.
Creating a Tiny Benchmark Dataset
To properly benchmark these speech-to-text APIs, I needed a diverse collection of audio clips that would test their performance across different conditions—background noise, accented speakers, and specialized vocabulary. I also wanted the clips to be long enough to evaluate punctuation and capitalization, since many speech recognition models struggle with formatting beyond single sentences.
At first, I looked into open-source datasets. Hugging Face has a benchmark called "ESB: A Benchmark for Multi-Domain End-to-end Speech Recognition", which compiles several commonly used speech recognition datasets. This seemed like a good starting point, but after taking a closer look, I decided they weren’t quite what I wanted for this benchmark:
The Common Voice dataset contains a lot of accented speech, but the clips are generally too short, often around 10 seconds or less. This makes it hard to test how well APIs handle longer passages with punctuation.
Another widely used dataset, LibriSpeech, consists of audiobook recordings from LibriVox. Because they are drawn from public-domain content, the language is often quite poetic and old-fashioned, and less relevant for benchmarking modern, everyday speech.
Since no existing dataset fully met my needs, I decided to build my own. I spent a few hours gathering audio clips with transcripts from different sources and manually verifying the transcripts for accuracy. Each clip was 1 to 2 minutes long, ensuring enough context to evaluate punctuation and sentence structure. The final dataset included around 30 minutes of speech across four key conditions:
Clean English Speech. For standard, well-articulated speech, I used TED Talk audio clips. These are native English speakers speaking about general topics with clear audio. Since the speech is high quality, I'm expecting all APIs should perform well in this category.
Noisy Speech. To simulate real-world background noise, I took the TED Talk recordings and added hospital noise to them. This mimics the busy environments that Voice Writer is often used, like hospitals or customer service centers.
Accented Speech. To test how well APIs recognize non-native English speakers, I used Spoken Wikipedia recordings read by speakers with Chinese and Indian accents. Voice Writer has users from all over the world with many types of non-native accents, so handling accents well is crucial.
Specialist Speech. For academic and technical content, I sourced recently published arXiv paper abstracts in fields like machine learning, mathematics, and physics; I then used Eleven Labs’ text-to-speech system to generate spoken versions of these abstracts. Ideally, I’d use human speech here but I'm assuming this setup is not biased in favor of any ASR provider, since Eleven Labs is separate from all of them.
The video version of the post contains samples of each audio condition. This is not really an exhaustive test of ASR setups since I focused mainly on the conditions relevant to Voice Writer, I didn't include anything like multi-speaker conversational speech or non-English languages, which are not currently supported in Voice Writer.
The Models and APIs We Tested
For this benchmark, I tested a mix of startup ASR models, cloud provider speech-to-text services, an open-source model, and a large language model with speech capabilities. Each of these systems claims to be highly accurate, but I wanted to see how they actually perform in real-world conditions. For each of these services, whenever they provided multiple models to choose from, I always selected the one advertised to have the highest accuracy, using default settings for all tests. All of these tests were conducted in January 2025.
First, the startups: two of the most well-known speech recognition startups are Assembly AI and Deepgram. Both offer simple API-based transcription services with clear documentation and easy integration. They allow you to upload an audio file and get a transcript back in just a few lines of code. Both Assembly AI and Deepgram claim to be better than their competitors, so this benchmark will reveal which one actually performs best.
Next, the major cloud providers - AWS, Google Cloud, and Microsoft Azure—also offer speech-to-text capabilities. One annoying thing for this benchmark is they all come with a lot more setup overhead. Unlike Assembly AI and Deepgram, where you can simply upload an audio file and transcribe it, these services required a bunch of extra steps. For example, with AWS Transcribe, you have to first upload your file to S3, call an API to create a transcribe job that takes the file from one cloud bucket and output into another cloud project, wait for the transcription to be processed, then download the transcribed file in JSON format back from the output S3 bucket to read its contents.
Google and Microsoft Azure follow similar multi-step processes, and each has its own set of permissions and access controls that need to be properly configured (eg, for the transcription service to have permission to read the input cloud bucket). This was the least fun part of this benchmark. If your application already stores data on AWS, Google Cloud, or Azure, these services might be convenient. But if you're just looking for a straightforward API, Assembly AI or Deepgram will be much easier to implement.
Next, I benchmarked the OpenAI Whisper model, the only open-source speech recognition model in this benchmark. Unlike the API-based services, you can run Whisper locally on your own hardware (you can also run it on a cloud provider though for more convenience). I tried two setups:
First setup I tested is Faster Whisper, an optimized version that allows you to run Whisper on either a GPU or CPU. I used Whisper Large V3 on a GPU; while smaller Whisper models can run on a CPU, the largest and most accurate version requires a GPU for reasonable processing speed.
I also tried a cloud-based Deepgram-hosted Whisper. This uses Whisper Large V2 combined with some proprietary preprocessing and postprocessing; in my tests, this implementation performed slightly better than my local setup (but less than 0.5%). For simplicity I'll just use this hosted version of Whisper for the rest of this benchmark.
The last API in this benchmark is Google Gemini. This is a bit different from the other models: instead of being a dedicated ASR model, it’s a large language model that can process audio. To transcribe speech, you attach the audio file with a text prompt like "please transcribe this audio as accurately as possible" and send it to Gemini, which gives back a transcript.
Multimodal LLMs like Gemini is a relatively new approach to speech recognition, but it's likely we’ll see more LLM-based ASR models in the future. Currently, Gemini is the only mainstream LLM that supports direct speech input, though OpenAI and Anthropic will likely add this capability soon. For this benchmark, I tested Gemini 1.5 Pro as well as the Gemini 2.0 Flash Experimental models but their performances were very similar so I'll just assume 1.5 Pro for the rest of the benchmark.
Measuring Speech Recognition Accuracy
When evaluating speech-to-text models, we use Word Error Rate (WER) as the primary metric. WER measures how well a speech recognition system transcribes audio by counting three types of errors: insertions, deletions, and substitutions—all relative to the total number of words in the correct transcript.
However, not all errors are created equal, especially when it comes to capitalization, punctuation, and minor spelling variations. For example, the number “two” could be written as "2," and the word “color” vs. “colour” may vary based on regional spelling. These inconsistencies can impact WER, even when the transcription is technically correct.
To account for this, we also use Unformatted WER (sometimes called Normalized WER), which removes punctuation, capitalization, and standardizes spelling before calculating errors. This version of WER provides a clearer measure of raw transcription accuracy, focusing purely on word recognition rather than formatting.
For example, consider the following transcription:
Reference: “Yes you’re right – the cups come in two colors.”
Output: “Yes, you are right. The cups come in 2 colours.”
Normalized: “yes you are right the cups come in two colors”
In this case, the Unformatted WER would disregard differences in punctuation, contractions (“you’re” vs. “you are”), number formatting (“two” vs. “2”), and regional spelling (“color” vs. “colours”), ensuring that only word recognition accuracy is measured.
Why use both formatted and unformatted WER? Both versions of WER are useful in different contexts:
Formatted WER (with punctuation and capitalization) is important for applications like writing assistants, where properly formatted text is crucial.
Unformatted WER is better suited for use cases like voice assistants or machine learning pipelines, where text formatting is often stripped away anyway.
Since these two approaches serve different purposes, we include both in this benchmark to give a complete picture of speech-to-text accuracy.
Results: Best APIs for Speech Recognition
Now for the results we’ve all been waiting for - let's start looking at each speech setting, then compare the overall rankings.

For the clean speech category, every model performed fairly well, WER below 10% when formatting wasn’t required. However, once formatting is measured, error rates increased by about 10% across the board, with more noticeable differences between models.
The best performer in this category was OpenAI Whisper, in first place for both formatted and unformatted transcriptions. Deepgram and Gemini followed closely, within 2% WER of Whisper. Assembly AI was also strong in raw accuracy but struggled more with formatting.

Moving to noisy speech, overall performance dropped slightly—typically 1–2% worse than in the clean speech category. Some models handled noise better than others. Whisper, Assembly AI, and AWS Transcribe performed better, showing strong resilience to noise; on the other hand, Microsoft and Google Cloud ASR struggled more in this setting and consistently ranked at the bottom.
OpenAI Whisper remained the best model when formatting was required, while in the unformatted case, Assembly AI and Whisper tied for first place. Gemini also held up decently well under noise but wasn’t as strong as the top performers.

For speech with non-native accents, there was a major shake-up in the rankings. Google Gemini was the clear winner, outperforming all other models, whether formatting was required or not. Whisper, Assembly AI, and AWS also performed reasonably well in this category. Again, coming in last place is Google’s cloud ASR, with a disastrous average WER of 35% on accented speech.

For specialized speech, the winner again is Google Gemini, taking first place in both the formatted and unformatted categories. This is I think where LLMs really shine - unlike traditional ASR models, Gemini has world knowledge of technical terms, making it much better at transcribing them correctly.
Whisper and Assembly AI also performed well here, ranking above the other APIs. Interestingly, some models even had lower WER in this test than in clean speech, likely because the Eleven Labs TTS-synthesized audio was clearer than real human recordings.
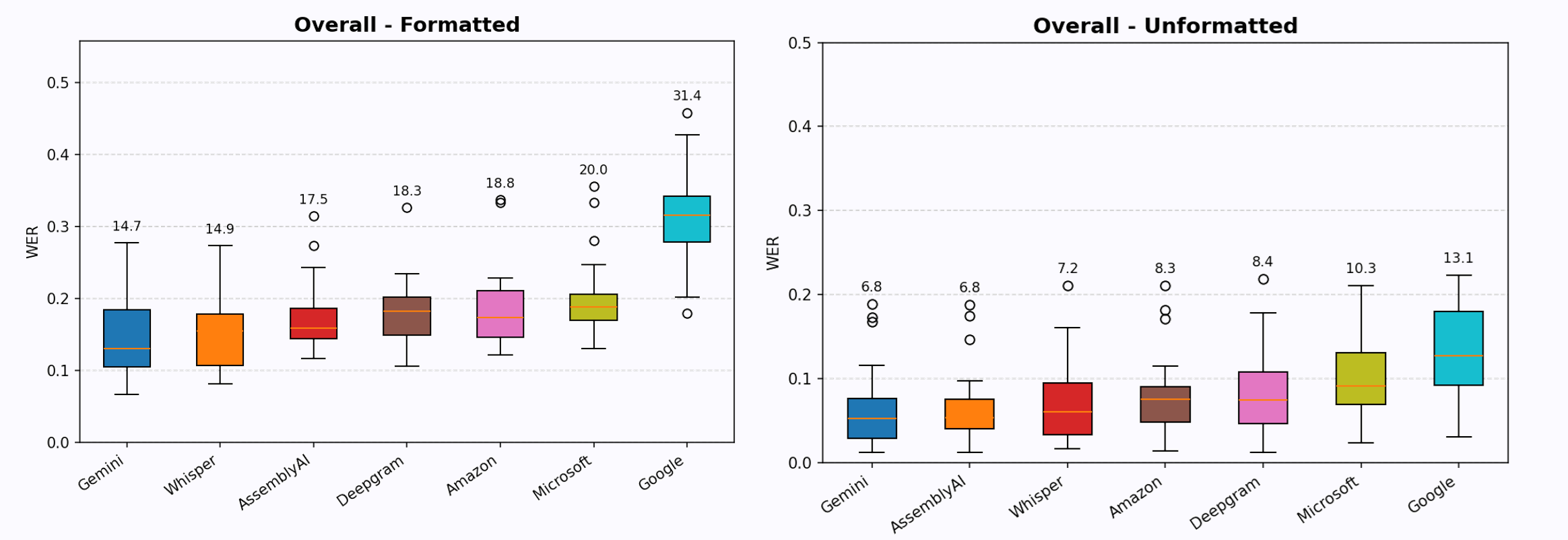
Looking at the overall rankings, Whisper and Gemini are tied for first place. Whisper stands out for its robustness to noise, while Gemini is better at handling accents and technical speech. The rankings remain fairly consistent across different conditions—Google’s cloud ASR is always in last place, Microsoft Azure is consistently in second last place, and AWS and Deepgram stay in the middle of the pack. Assembly AI is strong, often ranking near the top for unformatted transcriptions, but struggles slightly with formatting.
What happened to Google?
One of the biggest surprises of this benchmark was just how poorly Google Cloud ASR performed. The gap was so large that I double-checked my setup to ensure there wasn’t a mistake in my testing process, and looked at other benchmarks, and confirmed (such as Deepgram's benchmark and this academic benchmark) that Google Cloud ASR always ranks last, sometimes by a significant margin. At the same time, Google's Gemini is among the best models.
I think the most likely explanation is Google has shifted its focus to Gemini, directing its best talent and resources toward LLM-based AI models while neglecting its older speech recognition service. The cloud ASR model seems to be stagnant, and falling further and further behind every year. But if anybody reading this has any insight into what's happening with Google’s ASR, I’d be curious to know whether this is the case.
Real-time Streaming Speech Recognition
So far, this benchmark has focused on batch ASR, where you upload an entire audio file and receive a full transcript once processing is complete. In a real-time streaming setup, the API needs to process incoming audio with a short latency (typically on the order of 1-3 seconds) while maintaining high accuracy. Since the model doesn’t have access to the full context of a sentence like it does in batch mode, we can expect slightly lower accuracy.
Most of the APIs I've tested offer both batch and streaming ASR, except for Gemini, which currently does not support any real-time streaming. I was so far not too impressed with Google and Microsoft's batch ASR, so decided not to bother with testing their streaming APIs. This left me with 4 contenders: AWS Transcribe, Assembly AI, Deepgram, and Whisper Streaming.
The situation for Whisper is interesting enough to be worth noting. Whisper wasn’t originally designed for real-time ASR, but the community has devised clever setups to make it handle real-time streaming ASR. One such project is Whisper Streaming, which essentially chunks the audio and transcribes it incrementally. If you’re curious about how this works, I have a video here explaining it in detail. For this benchmark, I used Whisper Large V3 with Faster Whisper and GPU inference, keeping everything at default settings as usual.

Here are the results. Right away, it’s clear that streaming ASR models take a noticeable hit in accuracy compared to their batch counterparts. The drop in performance is most evident when formatting is required, the WER increases by 6-7% compared to batch, which is a significant decline. However, if formatting isn’t required and we only look at raw word recognition, the drop in accuracy is much smaller—about 3% increase in WER if formatting is not required.
Among the real-time models, AWS Transcribe and Assembly AI performed the best—but only when formatting wasn’t required. These two models were generally the most accurate at recognizing words in streaming mode, but they struggled with punctuation.
A major issue with all streaming ASR models is how they handle punctuation. Unlike batch ASR, where the full sentence is processed at once, real-time models have to decide on punctuation as they go, without knowing what comes next. This results in excessive sentence fragmentation, where long, natural sentences are broken up into multiple shorter sentences. For example, here is a typical output (from Assembly AI, which had the worst case of this issue, but all the models had this problem to various degrees):
"Here's our new law. Firm. We have the best lawyers with the biggest clients. We always perform for our clients, do business. With us. Here’s. Our new car. It gets great gas mileage."
Here the model generated 8 very short sentences when the original transcription is only 2 sentences. This is an issue because when speakers pause briefly, it's hard for the model to know whether it should predict a period, a comma, or nothing at all. Due to this problem, formatted WER for all streaming models was consistently above 20%—much higher than their batch-mode counterparts.
However, when punctuation and capitalization were ignored, the accuracy was much more reasonable. If you’re building an application that requires real-time speech recognition, given how unreliable formatting is in streaming mode, you may be better off stripping the punctuation and work with unformatted transcriptions.
The Whisper Streaming model was one of the stronger performers in formatted text, but it came with reliability issues that make it difficult to recommend for production use. Some of the problems I encountered included:
Inconsistent punctuation—in two test cases, it suddenly stopped outputting punctuation altogether.
Missing words—in one file, it dropped large portions of the transcript.
Hallucinated phrases—in three files, it randomly added text that wasn’t in the original speech, such as “Thank you for watching”.
These issues likely stem from the fact that Whisper was never designed for real-time streaming, and the streaming implementation is essentially a workaround built on top of a model trained for batch processing. It may be fixable but I wasn't able to find a solution by tweaking the settings, so I would be hesitant to use Whisper Streaming in a production use case.
So, which model is the best for real-time transcription? If formatting is required, there’s no clear winner -- none of the models perform well enough that I'm happy with. However, if you only need raw transcriptions, AWS Transcribe and Assembly AI tie for first place, with better accuracy than Deepgram and Whisper Streaming, as long as you can work with unformatted text and handle punctuation separately.
Final Rankings
Now that we’ve gone through all the benchmarks, let’s break down the final rankings—from best to worst. Some models consistently delivered strong results, while others fell far behind.

Before deciding on the best ASR models, let’s get the worst ones out of the way first. Without a doubt, Google’s ASR was the worst performer in this benchmark. It came dead last in every test, often by a huge margin, no matter if it was clean speech, noisy environments, accents, or technical speech, formatted or not, Google’s model was last place in every category.
Microsoft Azure: slightly better than Google, but still a poor choice overall, coming in second-to-last in most categories. The only scenario where it might make sense is if your data is already inside Microsoft’s cloud ecosystem.
The best two models clearly stood out: OpenAI Whisper and Google Gemini. They are statistically tied for first place in this contest, and one of them always comes in first place depending on the scenario. Whisper is slightly better at handling noisy environments, whereas Gemini is a bit better at accents and technical vocabulary, but both are great choices for state of the art speech recognition.
Assembly AI is another strong contender, especially for unformatted speech. It performed very well in raw word accuracy but struggled slightly when generating formatted text with punctuation. AWS Transcribe and Deepgram sit in the middle of the pack, delivering consistent but not exceptional results. AWS is a good option if you’re already using AWS cloud services, while Deepgram is a convenient API that performs decently.
For real-time streaming ASR, the best options are AWS Transcribe & Assembly AI. Both models performed equally well, but only when formatting is not required. However, at this point, no model is reliable enough for generating perfectly formatted text in real time.
That’s it for this benchmark. If you found this useful, give Voice Writer a try: not only do we use the best models to transcribe your speech, we also fix your wording and punctuation in real time so you can just paste it into any document you're writing like an email, blog post, or chat message. Sign up for free today!