A Streaming Proxy for Real-Time ASR: Abstracting Speech Providers
Jul 9, 2025
How does Voice Writer turn speech into grammatically correct writing in real time? Most voice apps record everything first and only process it afterward. Voice Writer works differently: we use streaming ASR and LLMs to deliver sub-second latency as you speak. In this post, we’ll walk through the real-time architecture that enables low latency, high reliability, and the ability to seamlessly swap out speech providers as better models become available.
Problem 1: Real-Time Requirements
Most existing voice apps follow a simple pattern: you speak, they record everything, and when you're done they begin transcribing. We found this approach deeply flawed: it requires the user to trust that their entire recording will be processed correctly after the fact. There are serious risks around error handling -- if anything fails mid-process (network error, the model is overloaded, etc), it's difficult to recover, and in our experience, in most cases the entire session is lost. If you’ve just spent 10 minutes dictating an email in Voice Writer and it just vanishes, that's a terrible experience, and you're unlikely to trust the tool again.

That’s why we made the decision to stream transcription in real time. This way, users see words being recognized within a second and immediately know whether things are working. If something goes wrong, at least partial progress is visible and can be saved, rather than everything vanishing silently.
Problem 2: Speech Backend Fragmentation
Another challenge: every speech provider exposes a different API, with different combinations of authentication methods, input formats, audio codecs, output schemas (e.g., languages, confidence scores, channels), and handling of partial vs. final transcripts. Managing these differences in our frontend logic (in the web app and Chrome extension) would be difficult to maintain.
On top of that, the best ASR model is constantly changing. Performance varies by language, speaker accent, acoustic conditions, topic, among other things. We track this with our benchmarks, and the winner changes from one month to the next as providers improve their models.
To keep up, we needed flexibility: the ability to switch speech providers easily and expose a simple interface to the frontend -- one where you just change the model id to switch providers. With our grammar correction LLMs, we use OpenRouter as an abstraction layer, where switching from Claude to Gemini is a one-line change. But in speech recognition (especially streaming ASR), there is not yet any OpenRouter equivalent. So we built our own.
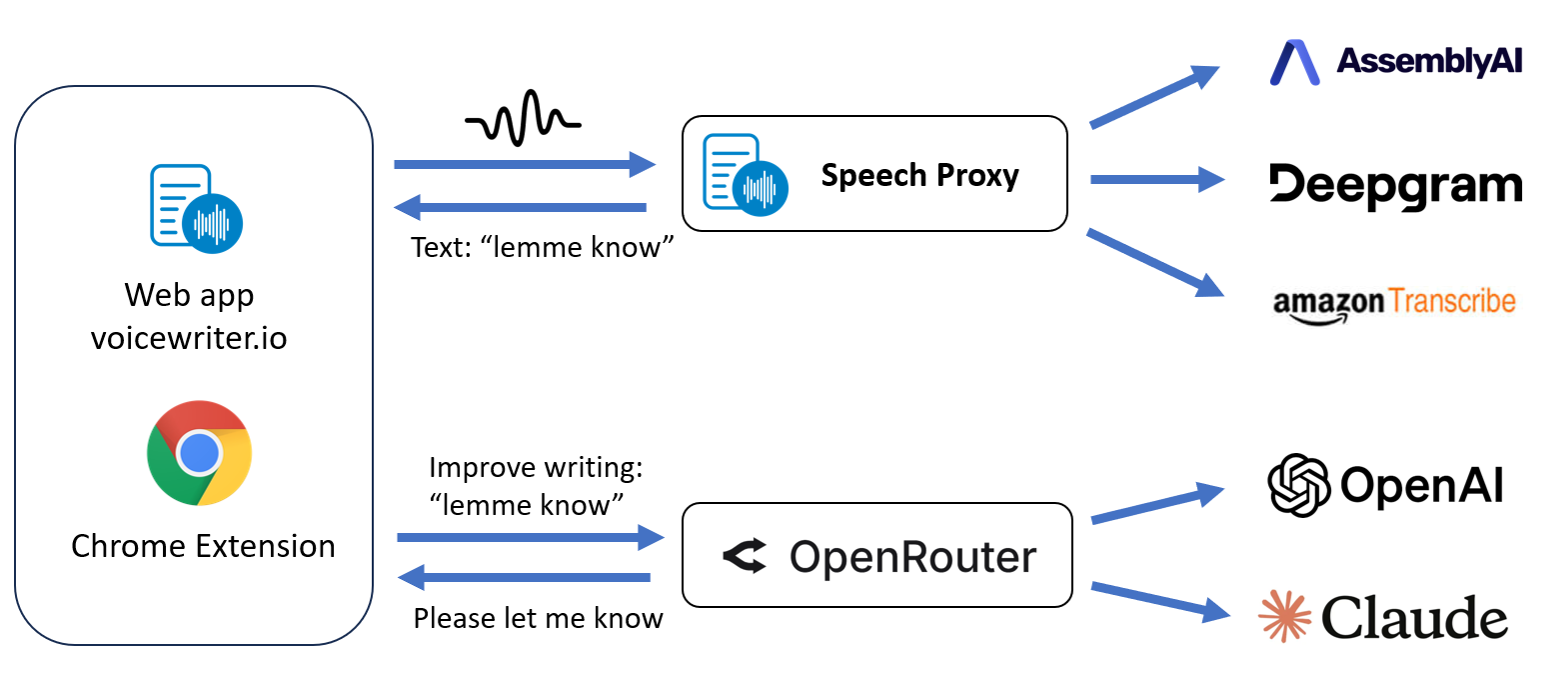
Solution: Real-Time ASR via a Streaming Proxy
The solution we developed is a speech proxy server that sits between the client and the speech recognition backend. It maintains two active WebSocket connections: one between the client (browser) and the speech proxy, and another between the speech proxy and the ASR provider. The WebSocket protocol allows for real-time, bidirectional communication: the client streams audio to the server, which forwards it to the provider, and the provider sends back partial and final transcriptions in JSON format.
But why a proxy server at all? Because we need a layer that manages multiple responsibilities across connection, security, format compatibility, and provider abstraction. The proxy is responsible for the following core functions:
1. Secure Authentication. Most ASR providers require API keys for authentication, but exposing those keys to the browser is a no-go -- any user could extract and misuse them. Instead, our proxy authenticates the client using session cookies, and attaches the appropriate API key server-side, keeping all secrets off the frontend.
2. Real-Time Format Conversion. ASR providers typically expect raw audio in 16-bit signed PCM format at 8000 or 16000 Hz. However, browser microphones using the MediaRecorder API streams audio in a compressed WebM format containing Opus-encoded audio at 44.1 kHz or 48 kHz. The proxy handles real-time audio decoding and resampling to stream audio to the provider in a compatible format.
3. Unified Message Formats. Each provider has its own quirks: different input options (model selection, language codes, punctuation settings, etc) and different output schemas (text fields, timestamps, confidence scores, etc). Our proxy abstracts these differences by normalizing both request and response formats into a unified schema. This means the frontend only needs to understand one protocol, regardless of which speech provider is active behind the scenes.
4. Connection Management and Reliability. The proxy also handles connection lifecycle logic: supporting multiple concurrent clients, managing timeouts, and ensuring clean shutdowns on both sides if either the client or provider goes silent. While most ASR providers offer client libraries to manage these details, each one handles connections a bit differently. Instead, we found it cleaner to unify message formats at the WebSocket protocol level and reimplement all the necessary connection management logic ourselves.
Partial and Final Transcripts: Latency Optimizations
Most ASR providers distinguish between partial and final transcripts. Partial transcripts are low-latency and show up almost instantly, but they may change as more audio is processed. Final transcripts are stable and won’t change further.
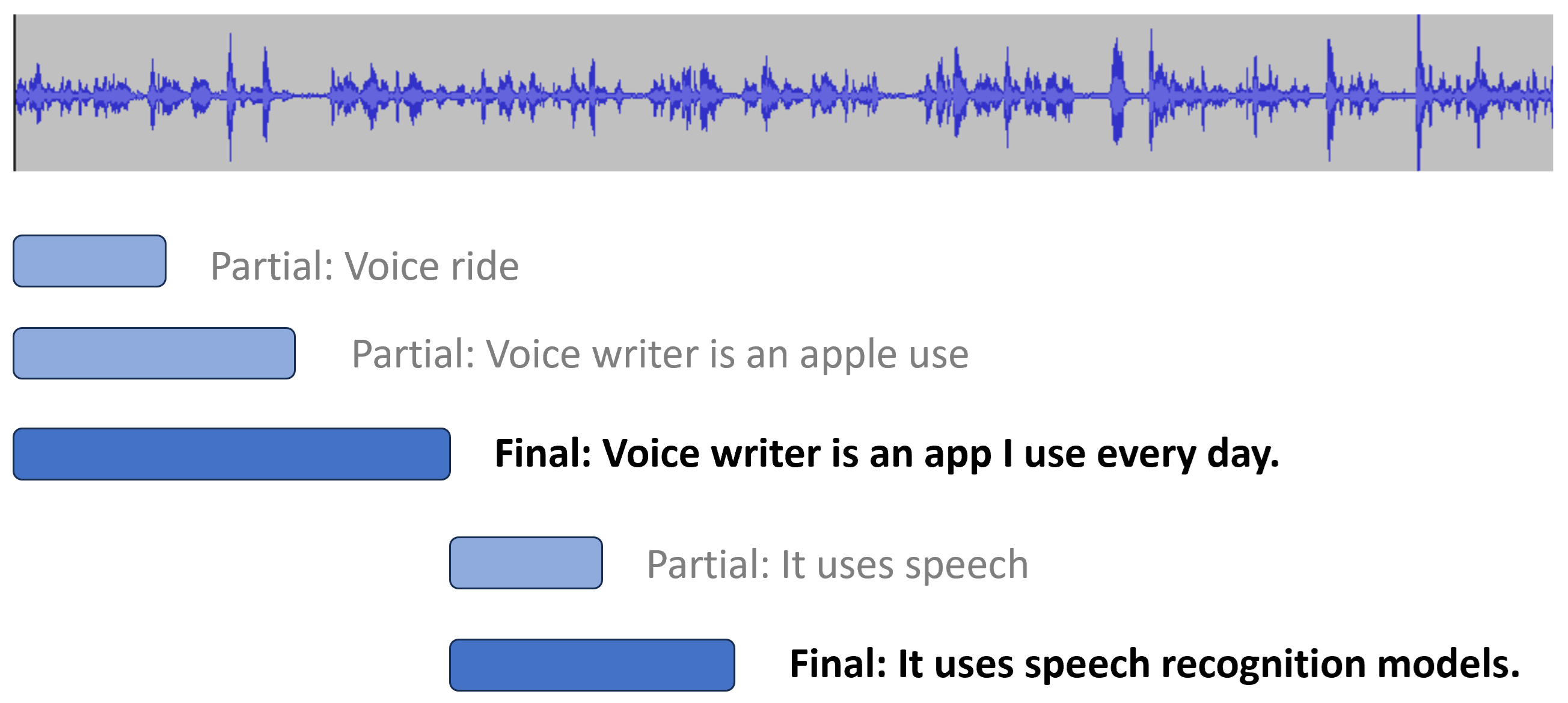
Showing partial transcripts improves perceived latency by a few seconds. For example, Whisper Streaming can generate partial transcripts in under 0.5 seconds, with average final latency of 3-5 seconds.
Some ASR providers also support manual finalization. Normally, final transcripts are emitted after detecting silence (via VAD), generating punctuation, or based on heuristics when the same partial transcript is generated sufficiently many times. But when the frontend knows the user has stopped speaking (when the stop button is pressed), we can signal the ASR provider to finalize immediately and cut down on wait time for the last segment. We add this in our protocol wherever the provider supports it.
Once the final transcript arrives, it's passed to a grammar correction LLM. This typically adds 1-2 seconds of latency until first token, then chunks are streamed from the LLM provider to the frontend via SSE (server sent events). Fortunately, this part of the ecosystem is relatively mature: OpenRouter automatically selects the LLM providers with the best uptime and latency dynamically. This entire streaming pipeline is built to minimize latency, so the user gets immediate feedback and minimal wait time as to not interrupt the writing flow.
Conclusion
The core idea of turning speech into grammatically correct text is a simple one, but making it work well in practice took a lot of thought and engineering. We've built a fast, robust system that I use every day and that many users rely on for their voice writing needs. Try it for free in your browser and experience the best speech models available for writing.
If this sounds interesting and you'd like to learn more, reach out to me here to discuss LLMs, speech recognition, or real-time AI apps!